

Why language models hallucinate for dummies
A non-technical breakdown for normal people with a social life.


Four main points:
A model will never be 100% accurate.
Hallucinations are a solvable concept, by abstaining from answering.
Hallucinations are the result of our LLM training reward framework (it’s not magic).
The reward framework needs to be rebuilt to reward uncertainty.
Ok, let’s start
We’ve all heard the old adage, say it with confidence and people will believe you.
It genuinely works. I do it all the time, this article for instance.
Just kidding. Sort of.
Turns out, AI does it too.
Your chatbot of choice, OpenAI, Gemini, Perplexity, Grok, etc sounds so sure of itself when it answers your question. Most of the time, it’s a fact, logical explanation or response that has a likelihood of being just plain wrong.
The technical term is hallucination. Very different from the ones those special mushrooms you once took in Amsterdam.
AI’s hallucinate because there is an element of prediction, in every response from a chatbot. Throughout this, I’ll speak through reference to ChatGPT byOpenAI, because they’re arguably the most well known. Case in point, look at this market share below. 6 billion visits to ChatGPT vs 750m to Gemini (it’s closest competitor).
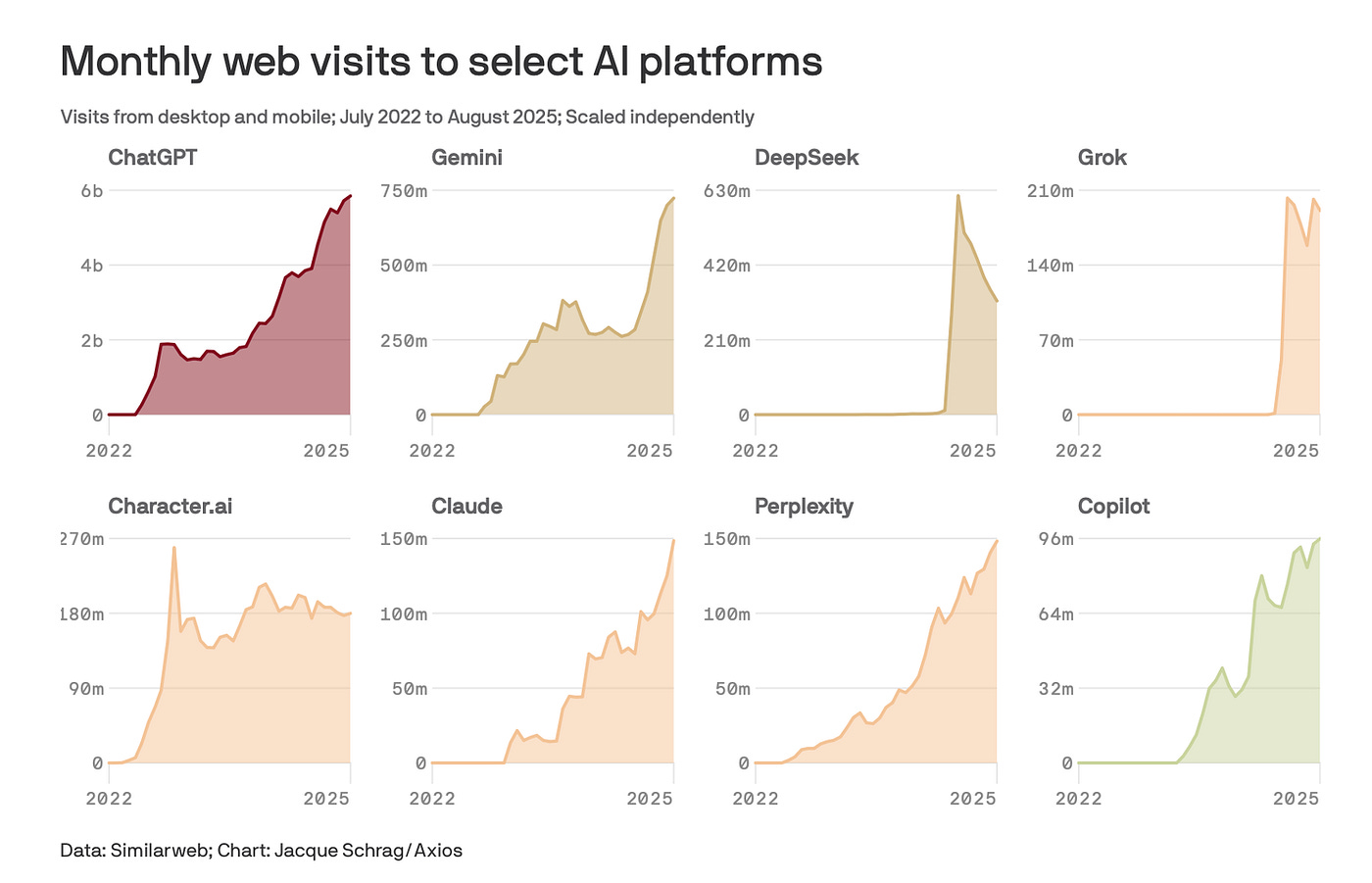
This concept applies all the above.
So to start, when ChatGPT responds to your question, there is always an element of chance and reasonable guessing. A chance to hallucinate. OpenAI and others have been trying to work out how to reduce these hallucinations. In this paper, aptly titled ‘Why Language Models Hallucinate’, they’ve apparently figured it out.
The paper is incredibly technical. Just look at this sexy algorithm.
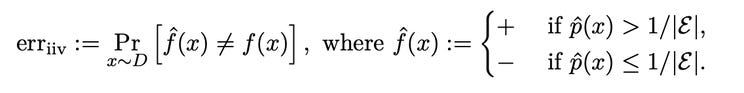
So, here’s what you need to know.
Language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty.
The core idea
Basically, ChatGPT hallucinates because when the models are trained, they are given direct instructions to provide a finite answer.
A binary yes or no.
Rather than being rewarded for saying I am not sure, or, I don’t have enough information to say unequivocally yes, or no, they are rewarded only if they say yes.
So when using the model, to actually answer your question as a user, the AI can really only have two different tasks to respond to you.
Marking an answer “does this look right?” Yes or No.
Writing an answer “produce this answer yourself”.
When testing the models’ answers, this paper found that if a model makes 5% mistakes at marking, it will make 10%, or 2x the amount of mistakes, in writing.
That is big enough to matter. Flashback to the Chevrolet Dealership which gave away a truck for $1 USD.
Imagine every 1/5 interactions was a practically free car.
A fun game for kids
To visualise this, Open AI created a simple quiz called “Is it valid”. The premise was to take a bunch of correct answers, mix in some wrong ones.
The LLM duck-duck goose.
The model was tasked to label each answer as valid or not. Then given a marker score. If the model was tasked with writing the answer from scratch, the error rate rose.
The takeaway. Writing is the hard part for LLM’s.
Why writing is hard
For most questions, there’s typically one (or few) correct answers. There are of course, countless wrong ones. An LLM basically spreads its bets about what is correct, across a huge space. In some of these spaces, it’s absolute fluent nonsense.
When ChatGPT says it’s 80% sure, it will be right about 80% of the time.
So what do most providers do to improve their model?
Calibrate.
Large base models often start out reasonably calibrated. After more fine-tuning to sound more helpful and human, weirdly it actually goes down.
A smoother tone, but with an accuracy decline.
But the real question is, what is accuracy. In these tests, we grade like we’re in school. One point for correct, zero for “I don’t know”. So what happens, the LLM wants the points.
Answer, even if you’re not sure. It’s like the AI is channeling Jordan. You miss 100% of the shots you don’t take.
Guess who
Imagine now a quiz where each question has one exact true sentence. Every other sentence is wrong, with no pattern linking the questions. Unless the model memorises the exact answers during training, it’s guessing.
For so many answers, it is a guess. An educated guess, but a guess all the same.
OpenAI actually explained this pretty well. They said, suppose a language model is asked for someone’s birthday but doesn’t know. If it guesses “September 10,” it has a 1-in-365 chance of being right. Saying “I don’t know” guarantees zero points. Over thousands of test questions, the guessing model ends up looking better on scoreboards than a careful model that admits uncertainty.

Probably why reinforcement learning is so important in training.
In terms of accuracy, the spec shows that the older OpenAI o4-mini model performs better. However, its error rate (rate of hallucination) is significantly higher. Strategically guessing when uncertain improves accuracy but increases errors and hallucinations.
Realistically though, some questions can genuinely not be answered at all.
A lock without a key
Ok, perfect example.
“Decrypt this message without the key.”
With strong encryption, there is no efficient method that does this reliably. A refusal or a failure there is not incompetence, but it is honesty about the rules of the problem.
It is a reminder that not every “hallucination” is fixable with more data or nicer wording.
Sometimes the only sensible output is “cannot be done with what you gave me”.
This, is really hard for a type A LLM to admit.
Why existing test methods fail
There is actually a relatively straightforward fix that has been proposed over the last couple of years.
Penalise confident errors more than you penalise uncertainty.
Give partial credit for appropriate expressions of uncertainty.
OpenAI thinks it won’t work. In their own words, if the main scoreboards keep rewarding lucky guesses, models will keep learning to guess.
Unfortunately, the paper talks more about understanding the problem, rather than creating solutions.
Perhaps when they find the answer, they’ll make a paper for us dummies minus all the mathematical theorems.
—
If you’re interested in the actual full paper, OpenAI published it here. https://openai.com/index/why-language-models-hallucinate/
—