

Salesforce was right to turn of Slack API access
Models become obsolete, margin lives inside Slack’s private memory.


What a surreal moment.
Slack flipped one switch and Glean’s access went dark.
That blackout exposed a truth many have missed. In the AI race, profit lives in proprietary memory, not in application code.
Salesforce saw the writing on the thread
For years, open APIs were the norm.
Anyone could hook into Slack, bolt on features, and ride its growth curve.
That made sense when usage growth created the most value.
Here’s the but…
BUT.
Today the value hides elsewhere. Large-language models sharpen on fresh, private conversations far better than on public text.
If Salesforce left its firehose wide open, rivals would train on those chats, copy Einstein’s answers, and pay Slack nothing.
Closing bulk exports looked harsh, but it was a clean math play.
Protect the memory, protect the margin.
Quote me on that.
Open pipes are now subsidies for companies
Hear me out.
An open API feels generous, yet it gives free training data to everyone while Slack pays the storage and compliance bill.
Each exported channel message teaches an outside model how Slack users think. Those insights return as competing products that sell back into the same workspaces. Open pipes turned into a subsidy for competitors.
All Salesforce did, was replace that subsidy with a meter.
Pay for each sip or build inside their marketplace where the house keeps a cut. The margin moved from hosting messages to owning them, and Slack followed the money.
So Blake, where does the margin live?
TLDR: Human behaviour, in json format.
{
"insight": {
"category": "human behaviours",
"type": "absolute gold"
}
}Well, it’s pretty clear that switching costs have fallen. Migration tools are cheap and interfaces copy one another in months.
What holds people now is data gravity, the pull of a unique memory bank.
Tesla owns billions of real-world miles.
Netflix owns granular watch histories.
Slack owns ten years of daily decisions and debates.
That archive improves Einstein Copilot in ways no one can match.
Models will converge. The memory that trains them will not. Guarding that archive locks in users and profit.
From exhaust fumes to inventory
There are so many damn applications with chat.
Let’s face it, chat logs used to feel like exhaust fumes that clogged servers.
In 2025 they are premium stock.
I recently wrote about Reddit charging eight-figure fees for archive access.
What I have recently found out, is that Stack Overflow plans to follow.
Yes that Stack Overflow. Bit late, I know.
Cue the new Q&A curve graph below:
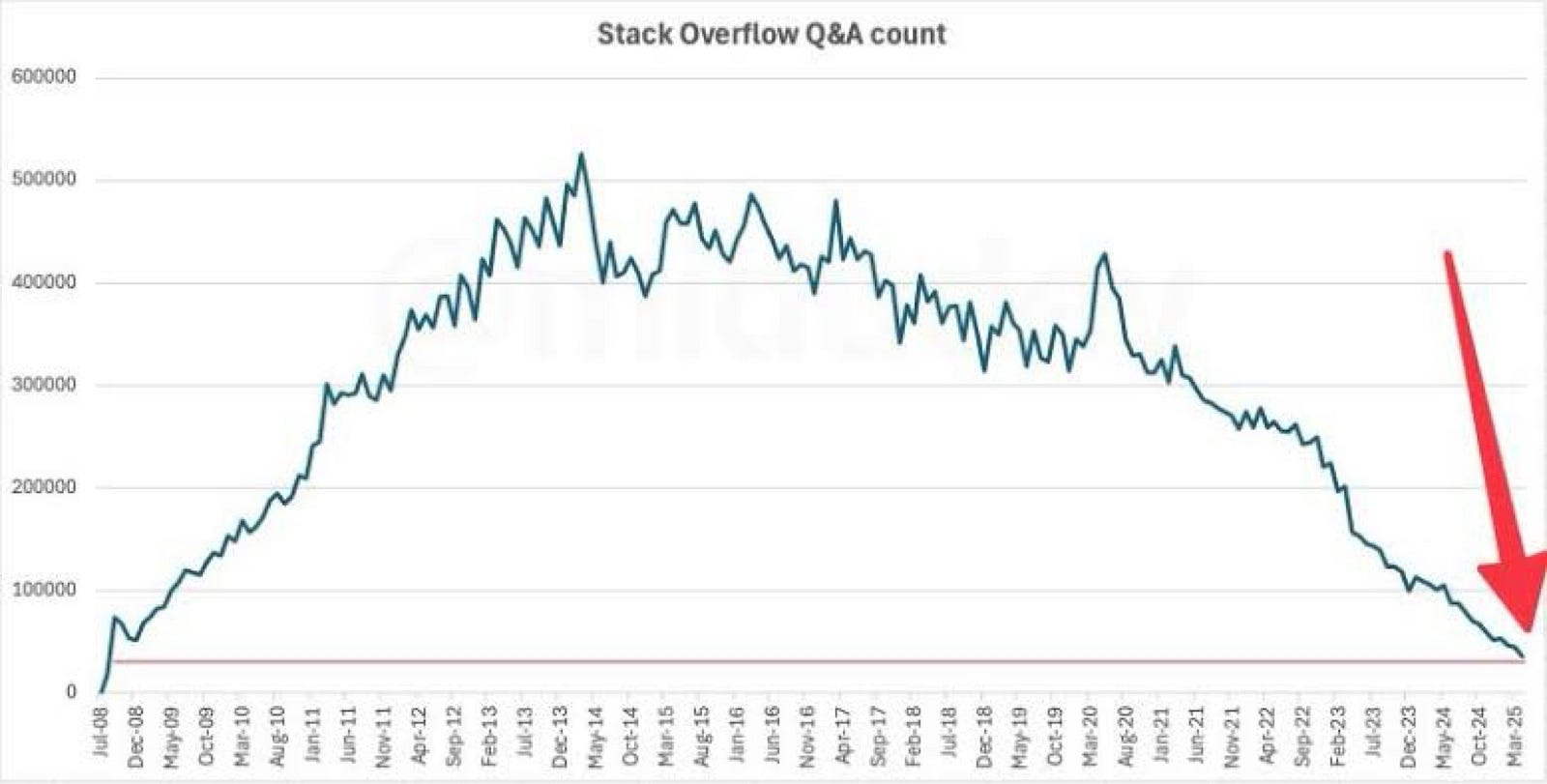
One word. Ouch.
BUT. For Slack, who has the benefit of ‘first-mover advantage’, Slack’s new Real-Time Search API is a controlled tap.
Small bursts cost money. Full flow only happens through native Einstein features.
Data storage shifts from expense to revenue. Privacy framing softens the optics, yet the plan is clear: keep margin by bottling memory.
So, they’re building for owned memory
Slack’s gate forced me to rewrite my product checklist.
Every new idea faces one question.
Do we create data we can keep?
If not, we live on someone else’s roadmap.
I back companies that capture their own signal.
Whoop records biometrics.
Toast logs restaurant orders.
Samsara collects sensor streams from moving assets.
The model can be open source or rented by the minute; the input must be ours. APIs are scaffolding, not foundations. When Glean broke, I felt the pain of renting data. Slack handed me the map to margin: own the memory or rent the future.
Get to the takeaway, Blake…
Salesforce saw where the margin lives and locked the gate. In a market where models level out fast, proprietary memory is the only advantage that lasts.
In other words, turn it off or become Stack Overflow.
